CONSTRAINED TRAJECTORY LEARNING

Contracting dynamical system primitives (CDSP): CDSP is a framework to learn the dynamics of movement skills (primitives) from expert demonstrations with theoretical guarantees. The desired motion is believed to be generated by an underlying stable time-invariant dynamical system. To capture the variations in the demonstrations, statistical models, such as Gaussian mixture models, are used to approximate the dynamics. The parameters of the statistical models are learned subject to the constraints derived using tools from dynamical systems theory. Enforcement of these constraints provide theoretical guarantees on the learned models, such as convergence to the desired target. Further the learned models instantaneously adapt to spatial perturbations and changes in goal location. The CDSP algorithm is capable of learning both end-effector position and orientation dynamics.
Selected publications:
- H. Ravichandar, A. P. Dani, “Learning Pose Dynamics from Demonstrations via Contraction Analysis,” , Autonomous Robots, 2018.
- H. Ravichandar, I. Salehi, A. P. Dani, “Learning Partially Contracting Dynamical Systems from Demonstrations”, Proceedings of the 1st Annual Conference on Robot Learning, PMLR, vol 78, 2017, pp. 369-378.
- H. Ravichandar, A. P. Dani, “Learning Contracting Nonlinear Dynamics from Human Demonstrations for Robot Motion Planning”, ASME Dynamics, Systems, and Control Conference 2015 – Best Robotics Student Paper Award.
PREDICTING HUMAN INTENTIONS FOR HUMAN-ROBOT COLLABORATION

Adaptive Neural Intention Estimator (ANIE): An algorithm to infer the intent of a human operator’s arm movements based on the observations from a Microsoft Kinect sensor. Intentions are modeled as the goal locations of reaching motions in the 3-dimensional (3D) space. Human intention inference is a critical step towards realizing safe human-robot collaboration. Human arm’s nonlinear motion dynamics are modeled using an unknown nonlinear function with intentions represented as parameters. The unknown model is learned by using a neural network (NN). Based on the learned model, an approximate expectation-maximization (E-M) algorithm is developed to infer human intentions. Furthermore, an identifier-based online model-learning algorithm is developed to adapt to the variations in the arm motion dynamics, the motion trajectory, the goal locations, and the initial conditions of different human subjects.
Selected publications:
- H. Ravichandar, A. P. Dani, “Human Intention Inference using E-M Algorithm with Online Learning”, IEEE Transactions on Automation Science and Engineering, vol. 14, no. 2, pp. 855-868, 2017.
- H. Ravichandar, A. P. Dani, “Human Intention Inference using Artificial Neural Network-based E-M Algorithm”, IEEE Intelligent Robots and Systems, 2015, pp. 1819-1824.
Multiple Model Intention Estimator with Gaze prior (G-MMIE): An algorithm to learn human arm motion from demonstrations and infer the goal location (intention) of human reaching actions. To stable nonlinear dynamical system is used to represent the arm motion dynamics. A statistical model is used to approximate the dynamics and is trained subject constraints derived using contraction analysis. To adapt the motion model learned from a few demonstrations to novel scenarios or multiple objects, an interacting multiple model framework is used. The multiple models are obtained by translating the origin of the contracting system to different known goal locations. The posterior probabilities of the models are calculated through interactive model matched filtering carried out using extended Kalman filters (EKFs). The correct model is chosen according to the posterior probabilities to infer the correct intention. The prior distribution over the possible goal locations (models) is derived based the human eye gaze information. The prior distribution helps in narrowing the number of possible goal locations to consider in the multiple-model framework. Furthermore, this work has been extended to learn and predict the steps involved in a sequential tasks. The varying temporal dependencies of a sequential task are captured using a recurrent neural network (RNN) with long short-term memory (LSTM) units.
Selected publications:
- H. Ravichandar, A. Kumar, A. P. Dani, “Gaze and Motion Information Fusion for Human Intention Inference”, International Journal of Intelligent Robotics and Applications, 2018.
- H. Ravichandar, A. Kumar, A. P. Dani, K. R. Pattipati, “Learning and Predicting Sequential Tasks using Recurrent Neural Networks and Multiple Model Filtering”, AAAI Symposium on Shared Autonomy in Research and Practice, 2016, pp: 331-337.
SYSTEM IDENTIFICATION FOR NEUROPROSTHESIS
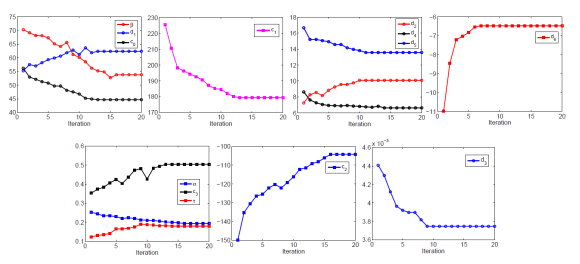
Identification of Electrically Stimulated Musculoskeletal Model: A system identification algorithm for a musculoskeletal system using an approximate expectation maximization (E-M). Effective control design for neuroprosthesis applications necessitates a well-defined muscle model. A dynamic model of the lower leg with a fixed ankle is considered. The unknown parameters of the model are estimated using an approximate E-M algorithm based on knee angle measurements collected from an able-bodied subject during stimulated knee extension. The parameters estimated from the data are compared to reference values obtained by conducting experiments that separate the parameters in the dynamics from one another.
Selected publications:
- H. Ravichandar, A. P. Dani, J. Khadijah-Hajdu, N. Kirsch, Q. Zhong, N. Sharma, “Expectation Maximization Method to Identify an Electrically Stimulated Musculoskeletal Model”, ASME Dynamics, Systems, and Control Conference, 2015.
IMAGE-BASED TEMPLATE TRACKING
User-guided Mutual Information Tracker (UGMIT): An image tracking algorithm that uses mutual information (MI) criteria for template matching and gyroscope information to predict rotation between two camera images. The tracking algorithm can also take a user input for template selection and update. The tracking algorithm uses Hu moments that are invariant to 2D rotation, translation, and scaling to validate the tracker. Homography is used to represent template warping parameters. The algorithm is aided with gyroscope measurements to estimate the camera motion information which helps to improve the initial guess of the warping condition. Template selection using a user’s input is based on properties of the target, such as it’s location in the frame. The user-driven strategy makes the tracker capable of tracking different objects of interest and might reduce the computational burden for template localization. The tracking algorithm presented in this paper shows significant improvements over recently developed gyro-aided Kanade-Lucas-Tomasi (KLT) tracker and the MI-only tracker and tracking in the case of multi-modal images.
Selected publications:
- H. Ravichandar, A. P. Dani, “Gyro-aided Image-Based Tracking using Mutual Information Optimization and User Inputs”, IEEE International Conference on Systems, Man, and Cybernetics, 2014, pp. 858-863.
